Introduction
Data processing frameworks, such as Apache Hadoop and Spark, have been powering the development of Big Data. Their ability to gather vast amounts of data from different data streams is incredible, however, they need a data warehouse to analyze, manage, and query all the data.
Are you interested in learning more about what data warehouses are and what they consist of?
This article explains the data warehouse architecture and the role of each component in the system.
What is a Data Warehouse?
A data warehouse (DW or DWH) is a complex system that stores historical and cumulative data used for forecasting, reporting, and data analysis. It involves collecting, cleansing, and transforming data from different data streams and loading it into fact/dimensional tables.
A data warehouse represents a subject-oriented, integrated, time-variant, and non-volatile structure of data.
Focusing on the subject rather than on operations, the DWH integrates data from multiple sources giving the user a single source of information in a consistent format. Since it is non-volatile, it records all data changes as new entries without erasing its previous state. This feature is closely related to being time-variant, as it keeps a record of historical data, allowing you to examine changes over time.
All of these properties help businesses create analytical reports needed to study changes and trends.
Note: Consider trying out Apache Hive, a popular data warehouse built on top of Hadoop. Learn how to install Hive and start building your own data warehouse.
Data Warehouse Architecture
There are three ways you can construct a data warehouse system. These approaches are classified by the number of tiers in the architecture. Therefore, you can have a:
- Single-tier architecture
- Two-tier architecture
- Three-tier architecture
Single-tier Data Warehouse Architecture
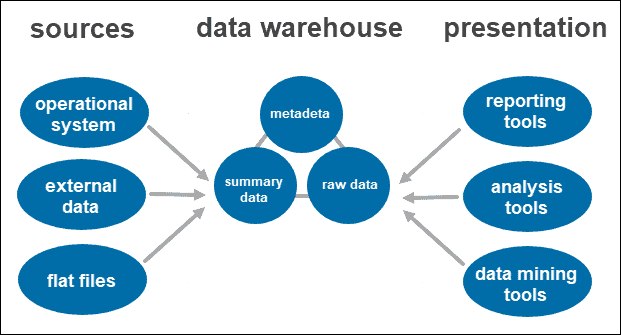
The single-tier architecture is not a frequently practiced approach. The main goal of having such an architecture is to remove redundancy by minimizing the amount of data stored.
Its primary disadvantage is that it doesn’t have a component that separates analytical and transactional processing.
Two-tier Data Warehouse Architecture
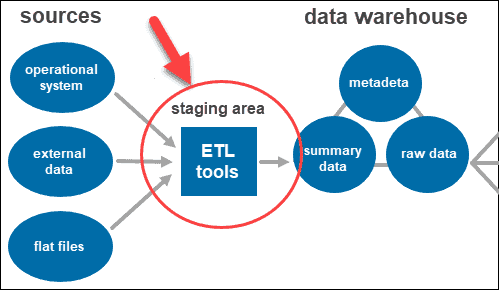
A two-tier architecture includes a staging area for all data sources, before the data warehouse layer. By adding a staging area between the sources and the storage repository, you ensure all data loaded into the warehouse is cleansed and in the appropriate format.
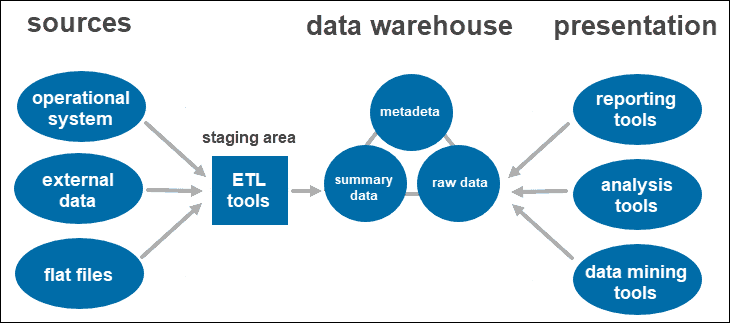
This approach has certain network limitations. Additionally, you cannot expand it to support a larger number of users.
Three-tier Data Warehouse Architecture
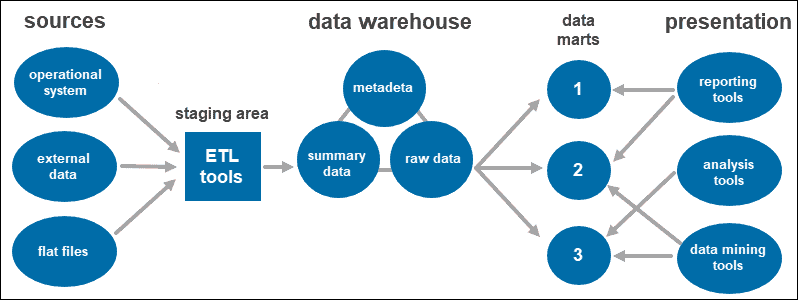
The three-tier approach is the most widely used architecture for data warehouse systems.
Essentially, it consists of three tiers:
- The bottom tier is the database of the warehouse, where the cleansed and transformed data is loaded.
- The middle tier is the application layer giving an abstracted view of the database. It arranges the data to make it more suitable for analysis. This is done with an OLAP server, implemented using the ROLAP or MOLAP model.
- The top-tier is where the user accesses and interacts with the data. It represents the front-end client layer. You can use reporting tools, query, analysis or data mining tools.
Data Warehouse Components
From the architectures outlined above, you notice some components overlap, while others are unique to the number of tiers.
Below you will find some of the most important data warehouse components and their roles in the system.
ETL Tools
ETL stands for Extract, Transform, and Load. The staging layer uses ETL tools to extract the needed data from various formats and checks the quality before loading it into the data warehouse.
The data coming from the data source layer can come in a variety of formats. Before merging all the data collected from multiple sources into a single database, the system must clean and organize the information.
The Database
The most crucial component and the heart of each architecture is the database. The warehouse is where the data is stored and accessed.
When creating the data warehouse system, you first need to decide what kind of database you want to use.
There are four types of databases you can choose from:
- Relational databases (row-centered databases).
- Analytics databases (developed to sustain and manage analytics).
- Data warehouse applications (software for data management and hardware for storing data offered by third-party dealers).
- Cloud-based databases (hosted on the cloud).
Data
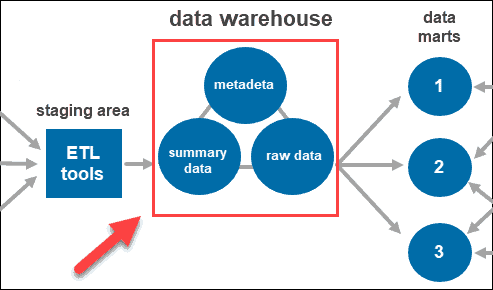
Once the system cleans and organizes the data, it stores it in the data warehouse. The data warehouse represents the central repository that stores metadata, summary data, and raw data coming from each source.
- Metadata is the information that defines the data. Its primary role is to simplify working with data instances. It allows data analysts to classify, locate, and direct queries to the required data.
- Summary data is generated by the warehouse manager. It updates as new data loads into the warehouse. This component can include lightly or highly summarized data. Its main role is to speed up query performance.
- Raw data is the actual data loading into the repository, which has not been processed. Having the data in its raw form makes it accessible for further processing and analysis.
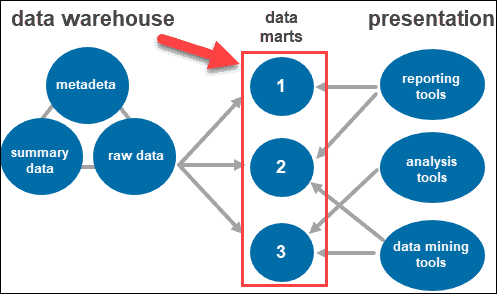
Access Tools
Users interact with the gathered information through different tools and technologies. They can analyze the data, gather insight, and create reports.
Some of the tools used include:
- Reporting tools. They play a crucial role in understanding how your business is doing and what should be done next. Reporting tools include visualizations such as graphs and charts showing how data changes over time.
- OLAP tools. Online analytical processing tools which allow users to analyze multidimensional data from multiple perspectives. These tools provide fast processing and valuable analysis. They extract data from numerous relational data sets and reorganize it into a multidimensional format.
- Data mining tools. Examine data sets to find patterns within the warehouse and the correlation between them. Data mining also helps establish relationships when analyzing multidimensional data.
Data Marts
Data marts allow you to have multiple groups within the system by segmenting the data in the warehouse into categories. It partitions data, producing it for a particular user group.
For instance, you can use data marts to categorize information by departments within the company.
Data Warehouse Best Practices
Designing a data warehouse relies on understanding the business logic of your individual use case.
The requirements vary, but there are data warehouse best practices you should follow:
- Create a data model. Start by identifying the organization’s business logic. Understand what data is vital to the organization and how it will flow through the data warehouse.
- Opt for a well-know data warehouse architecture standard. A data model provides a framework and a set of best practices to follow when designing the architecture or troubleshooting issues. Popular architecture standards include 3NF, Data Vault modeling and star schema.
- Create a data flow diagram. Document how data flows through the system. Know how that relates to your requirements and business logic.
- Have a single source of truth. When dealing with so much data, an organization has to have a single source of truth. Consolidate data into a single repository.
- Use automation. Automation tools help when dealing with vast amounts of data.
- Allow metadata sharing. Design an architecture that facilitates metadata sharing between data warehouse components.
- Enforce coding standards. Coding standards ensure system efficiency.
Conclusion
After reading this article you should understand the basic components of any data warehouse architecture. You should also know the difference between the three types of tier architectures.
